Remote IoT Batch Job Example: How To Process Data From Yesterday's Devices
Have you ever thought about how all those tiny sensors and smart gadgets out in the world keep track of things, especially when you need to look back at what happened a while ago? It's a pretty big deal, you know, when you have countless devices sending bits of information, but you don't necessarily need to react to every single one the very second it arrives. Sometimes, what you really need is to gather up all that information from, say, the whole day before, and then make some sense of it all at once. This idea of handling big chunks of data from remote internet-connected things, specifically focusing on a batch job example where you process data from yesterday, is actually quite fascinating and incredibly useful for many businesses.
When we talk about a "remote IoT batch job example remote since yesterday since yesterday," we're really looking at a clever way to manage and analyze information that isn't always flowing in real-time. It's about setting up a system that can patiently collect data over a period, like a full day, and then process it all together. This approach is, you know, quite different from constantly watching every single data point as it comes in. It helps make sure you get a complete picture without overwhelming your systems or your team with constant alerts.
This kind of setup, where you pull in data from remote devices that have been gathering information since yesterday, offers some really neat advantages. It lets you spot trends, fix issues you might have missed in the moment, and just generally get a much better handle on how your remote operations are doing. We're going to explore what this all means and, actually, how you might put something like this into practice. So, let's take a closer look at this particular way of handling information from your far-off gadgets.
Table of Contents
- What's a Remote IoT Batch Job, Anyway?
- Why Process Data "Since Yesterday"? The Need for Historical Insights
- Setting Up Your Remote IoT Batch Job: A Conceptual Walkthrough
- A Practical Scenario: Monitoring Remote Sensors from the Day Before
- Important Considerations for Your Remote IoT Batch Jobs
- Frequently Asked Questions About Remote IoT Batch Jobs
What's a Remote IoT Batch Job, Anyway?
Alright, let's break down what a "remote IoT batch job" really means. First, "IoT" stands for the Internet of Things, which is basically a huge network of physical objects embedded with sensors, software, and other technologies that let them connect and exchange data with other devices and systems over the internet. These can be anything from smart thermostats in homes to industrial sensors in factories or, you know, even tracking devices on vehicles. They are, essentially, things that gather information from their surroundings.
Then there's the "remote" part. This just means these IoT devices are often far away from where the data gets processed or used. Think of sensors on a farm miles from the nearest town, or perhaps environmental monitors in a distant forest. The data they collect needs to travel across networks to a central location, usually a cloud server, where it can be stored and looked at. So, it's not like everything is happening right next to you, which is a key part of this setup.
A "batch job," in simple terms, is a computer program that runs without much human interaction, usually on a schedule or when a certain condition is met. Instead of processing information one piece at a time as it arrives, a batch job collects a group, or "batch," of data and processes it all together. This can be, you know, much more efficient for certain kinds of tasks, especially when you have a lot of data that doesn't need immediate attention. It's like doing your laundry; you wait until you have a full load rather than washing one sock at a time.
When you put "remote IoT" and "batch job" together, you get a system where data from far-off connected devices is gathered up over a period, like a day or a week, and then processed all at once. This is, in some respects, quite different from real-time processing, where every single data point triggers an immediate action. Batch jobs are really good for tasks like daily reports, system health checks, or long-term trend analysis, where you need a comprehensive look at past information rather than instant reactions. It's a way to handle a lot of information without, you know, constantly being on high alert.
Why Process Data "Since Yesterday"? The Need for Historical Insights
You might wonder why we'd specifically want to process data that has accumulated "since yesterday." Well, there are several very good reasons for this, and it really comes down to getting a fuller picture of what's happening over time. For one thing, looking at data from the previous day lets you do some really good operational analysis. You can see how systems performed over a full cycle, identify patterns that might not be obvious in real-time streams, and, you know, spot any issues that developed slowly. It's like reviewing a whole day's worth of notes instead of just a few sentences here and there.
Another big reason is for compliance and reporting. Many industries have rules about keeping records of operations, environmental conditions, or equipment performance. Running a daily batch job that collects and processes all the data from the previous day makes it much easier to generate these reports accurately and efficiently. You can, for instance, create a summary of energy usage or temperature fluctuations for regulatory bodies without having to pull data manually every time. This is, frankly, a huge time-saver.
Resource optimization is also a key benefit. By analyzing historical data, you can figure out if your equipment is running as efficiently as it could be. Maybe a certain machine uses more power during specific hours, or a remote sensor consistently reports unusual readings at night. These insights, gathered from a day's worth of data, can help you make better decisions about maintenance schedules, energy consumption, or even, you know, how you deploy your devices in the future. It gives you a chance to tweak things for the better.
Furthermore, processing data "since yesterday" is particularly helpful when dealing with devices that have intermittent connectivity. Not all IoT devices are always online. Some might connect only periodically to send their accumulated data. A batch job is perfectly suited for this, as it waits for all the data to arrive before starting its work. This means you don't miss any information just because a device was offline for a bit. It's a pretty reliable way to make sure you get all the pieces of the puzzle, even if they don't arrive all at once.
Setting Up Your Remote IoT Batch Job: A Conceptual Walkthrough
Getting a remote IoT batch job up and running involves several steps, each playing a vital role in the overall process. It's like building a little assembly line for your data, where each station has a specific job. This walkthrough will give you a general idea of how it all comes together, from gathering the initial information to getting useful results. So, you know, let's look at the different parts.
Data Collection and Storage
The very first step is getting the data from your devices. Your IoT devices, whether they are small sensors or larger pieces of equipment, will collect information and then send it somewhere. Often, they send it to an edge device or a gateway, which acts as a local hub. This hub might do some initial filtering or bundling of the data before sending it further along. It's like a local post office, basically, sorting mail before it goes to the main sorting center.
Once the data leaves the edge, it usually heads to the cloud. Here, it needs a place to sit and wait for processing. This could be in something called a data lake, which is like a big, unstructured storage area, or a time-series database, which is specifically designed for data that changes over time, like temperature readings every minute. The key here is to make sure the data arrives safely and is stored in a way that keeps it intact. You want to be sure, you know, that every bit of information is there when you need it.
Ensuring data integrity during this collection and storage phase is super important. You need mechanisms to make sure data isn't lost or corrupted on its way from the device to the storage location. This might involve using secure communication protocols or having systems that confirm data has been received correctly. After all, if your raw data isn't right, then any analysis you do later won't be much help. So, you know, getting this part right is pretty foundational.
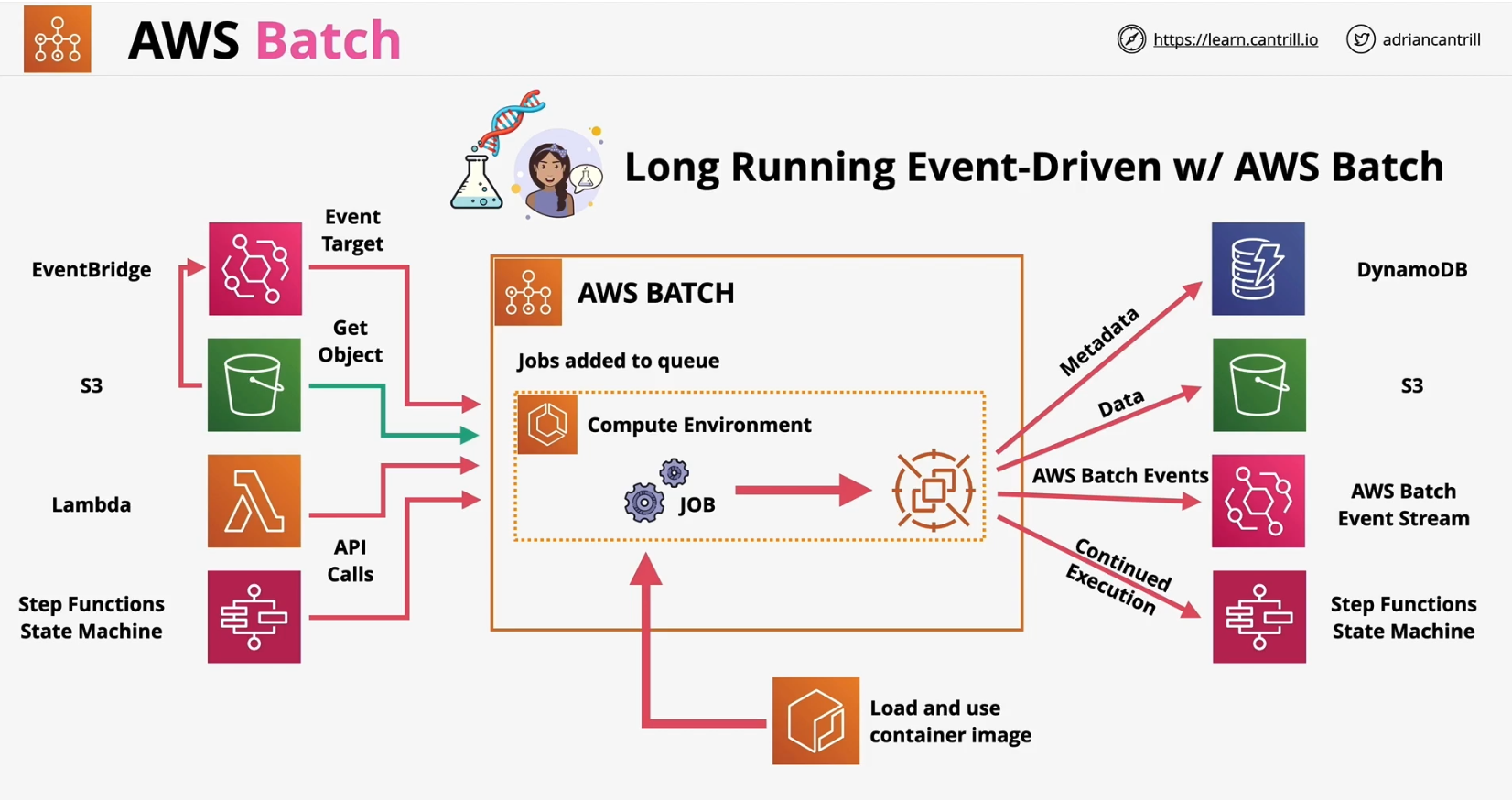
The Batch Processing Engine
Once your data is sitting in storage, you need something to actually do the work. This is where the "batch processing engine" comes in. This engine is essentially the computer program or service that will pick up all that stored data and start making sense of it. Many people use cloud functions or serverless compute services for this, like AWS Lambda or Azure Functions. These services are great because you only pay for the time your code is actually running, which can be, you know, very cost-effective for batch jobs that don't run all the time.
Another approach involves using containerized applications. Think of a container as a little self-contained package that holds your code and everything it needs to run. You can then deploy these containers on various cloud platforms. This offers a lot of flexibility and ensures your processing environment is consistent, no matter where it runs. It's like having a portable workshop that you can set up anywhere, which is quite handy.
To manage these processing tasks, you'll often use orchestration tools. These tools help coordinate when and how your batch jobs run, especially if you have several different tasks that need to happen in a specific order. They can, for instance, ensure that the data is fully collected before the processing starts. These tools make sure everything runs smoothly, almost like a conductor for an orchestra, which is, you know, pretty helpful for keeping things organized.
Scheduling and Triggers
How does your batch job know when to start? That's where scheduling and triggers come in. The simplest way is to set a time-based schedule. You might tell your system to run the batch job every day at 3 AM, for example, to process all the data from the previous 24 hours. This is, you know, a very common way to do things for daily reports or overnight analysis.
Alternatively, you can use event-driven triggers. This means the batch job starts when a specific event happens. For instance, it might kick off when a certain amount of data has been collected, or when a file is uploaded to a storage bucket. This can be really useful if the timing of your data collection isn't always predictable. It's like having a sensor that tells the system, "Okay, I'm full, time to process this batch!"
It's also really important to build in error handling and retry mechanisms. What happens if the network goes down for a minute, or if a processing step fails? Your system should be able to detect these issues and try again, or at least alert you so you can fix it. You don't want your entire batch job to fail just because of a small, temporary glitch. So, you know, planning for things to go wrong is pretty smart.
Data Transformation and Analysis
Once the batch job has picked up the raw data, the real work of making it useful begins. This often starts with data transformation. Raw IoT data can be messy; it might have missing values, incorrect readings, or be in a format that's hard to work with. So, the first step is usually cleaning it up, which might involve removing duplicates, correcting errors, or converting data types. It's like tidying up a room before you can really use it, more or less.
After cleaning, you'll apply business logic. This is where you define what you actually want to learn from the data. Are you looking for average temperatures, total energy consumption, or perhaps how many times a door opened? This step involves aggregating data (like calculating sums or averages), filtering it (only looking at data from certain devices), or combining it with other information. This is where you turn raw numbers into meaningful insights.
Finally, the batch job will generate reports or alerts based on its analysis. This could be a summary report showing daily performance metrics, a list of devices that reported unusual readings, or even an alert if certain thresholds were exceeded. The goal is to present the processed data in a way that's easy for people or other systems to understand and act upon. It's about, you know, making the information actionable.
Output and Action
After all that processing, what happens to the results? The processed data needs a home. This could be a different database, perhaps one optimized for analytical queries, or a data warehouse where it can be combined with other business information. Storing the processed data separately from the raw data is often a good idea, as it keeps things tidy and efficient for future use. This is, in a way, like putting your finished work in a dedicated filing cabinet.
Sometimes, the output of a batch job isn't just stored; it also triggers other systems or actions. For example, if the analysis shows that a certain machine is consistently overheating, the batch job could automatically create a maintenance ticket in your service system. Or, if daily energy consumption exceeds a budget, it might send an email notification to a manager. This is where the insights from your data lead to tangible outcomes, which is quite powerful.
Visualizations are also a common output. Taking the processed data and turning it into charts, graphs, or dashboards makes it much easier for people to grasp the information quickly. A daily dashboard showing key performance indicators from your remote devices, updated every morning by a batch job, can be incredibly valuable for decision-makers. It's about making complex data easy to see and understand, basically.
A Practical Scenario: Monitoring Remote Sensors from the Day Before
Let's imagine a very practical example to tie all these ideas together. Picture a company that manages a vast network of environmental sensors spread across a large agricultural area. These sensors, you know, collect various data points like soil moisture, air temperature, humidity, and sunlight levels throughout the entire day. They're constantly gathering information, but the farmers don't need to see every single reading as it happens. What they really need is a daily summary.
So, here's how a remote IoT batch job example remote since yesterday since yesterday would work for them. Every night, say around 1 AM, a scheduled batch job kicks off in the cloud. This job is specifically set up to pull all the environmental data that has been collected by every single sensor since midnight of the previous day. It gathers up, more or less, a full 24 hours of information. This includes data from sensors that might have had spotty internet connections during the day but managed to upload their stored readings when connectivity improved.
Once all that data is collected, the batch job gets to work. It cleans up any incomplete readings, averages out the sensor data for different zones, and then applies some specific agricultural logic. For instance, it might calculate the "evapotranspiration" rate for each field, which helps determine how much water the crops are losing. It could also identify any sensors that reported unusually high or low temperatures, which might indicate a problem. This is, you know, pretty important for managing the crops effectively.
By morning, say by 6 AM, the batch job has finished its work. It then generates a concise summary report for each field, highlighting key metrics like average soil moisture, temperature ranges, and any anomalies. This report is then automatically sent to the farmers' dashboards or their email inboxes. This way, when they start their day, they have a clear, easy-to-understand overview of the previous day's environmental conditions across all their fields. It's a very efficient way to get actionable insights without constant manual checking, which is, you know, a huge benefit for busy farmers.
Important Considerations for Your Remote IoT Batch Jobs
While setting up remote IoT batch jobs offers many benefits, there are several things you'll want to think about to make sure they run smoothly and effectively. Ignoring these can lead to problems down the road, so it's good to keep them in mind from the start. These considerations are, you know, pretty important for a successful setup.
Data Volume and Velocity
How much data are your devices generating, and how quickly? This is a big question. If you have thousands of sensors sending readings every few seconds, the sheer volume of data that accumulates "since yesterday" can be enormous. Your processing engine needs to be able to handle this load without getting bogged down. This might mean choosing more powerful cloud resources or designing your batch job to process data in smaller chunks. It's like making sure your car can carry all the groceries, you know, without breaking down.
Efficient data retrieval is also key. When your batch job goes to pull all that data from storage, you want it to happen quickly. If it takes hours just to get the data, your processing window shrinks, or your reports will be delayed. This often involves optimizing your database queries or using data storage solutions that are designed for fast reads. So, you know, speed matters a lot here.
Security and Access Control
Keeping your data safe is, frankly, non-negotiable. From the moment data leaves your remote device until it's processed and stored, it needs to be protected. This means using data encryption, both when data is moving across networks and when it's sitting in storage. You don't want sensitive information falling into the wrong hands. It's like putting a lock on your door, basically.
Authentication for devices and processing engines is also super important. Only authorized devices should be able to send data, and only authorized batch jobs should be able to access and process that data. Implementing strong access controls ensures that only trusted entities can interact with your IoT ecosystem. This is, you know, a very critical part of keeping everything secure.
Cost Management
Running cloud services can get expensive if you're not careful. For batch jobs, you have choices like serverless functions, where you pay per execution, or always-on virtual machines. Serverless options often make more sense for batch processing because they only consume resources when the job is actually running, saving you money during idle times. This is, you know, a pretty smart way to keep expenses down.
Optimizing data transfer costs is another consideration. Moving large amounts of data between different cloud regions or services can incur charges. Designing your architecture so that data processing happens close to where the data is stored can help reduce these costs. It's like trying to avoid long-distance shipping fees by buying local, more or less.
Error Handling and Monitoring
Things will go wrong sometimes, that's just how it is. Your batch job system needs to be ready for this. This means having robust error handling built into your code, so that if a particular data point is malformed or a connection drops, the entire job doesn't crash. It should try to recover or at least skip the problematic item without failing completely. So, you know, planning for hiccups is pretty wise.
Comprehensive logging and monitoring are also essential. You need to be able to see what your batch job is doing, when it runs, how long it takes, and if it encounters any problems. Setting up alerts for failures or unusually long run times means you'll know right away if something needs your attention. It's like having a good dashboard for your car, so you know if something is off, basically.
Data Retention Policies
How long should you keep the raw data from your devices, and how long should you keep the processed data? This is a question with both practical and legal implications. Storing massive amounts of raw data indefinitely can be expensive. You might decide to keep raw data for a shorter period, perhaps a month, and then only retain the summarized, processed data for much longer. This is, you know, a common practice to manage storage costs.
Compliance requirements often dictate how long you must keep certain types of data. Some regulations might require you to store specific operational data for years. Understanding these rules is important when defining your data retention policies. It's about balancing
- Sophie Rain Spiderman Erome
- Sasha Prasad Only Fan
- Gracie Bon Leaks
- Brattygbaby Porn Leaks
- Nicoleponyxo Nude
Mastering RemoteIoT Batch Jobs On AWS: A Comprehensive Guide

Remoteiot Batch Job Example Remote Aws Developing A Monitoring
Remoteiot Batch Job Example Remote Aws Developing A Monitoring
